


深度学习是近几年的热门研究话题。深度学习受到神经学的启示,模拟人脑的认知与表达过程,通过低层信号到高层特征的函数映射,来建立学习数据内部隐含关系的逻辑层次模型。深度学习相比于一般的浅层模型的机器学习方法具有多隐层结构,对大数据具有更好的拟合性。
传统的图像处理仅是单张或为数不多的数字图像的处理,而在今天信息爆炸的时代,对图像的处理更多地涉及到视频(图像流)的分析,每一副图像可能有数十万个像素点,而一段多帧视频若有成百上千幅图像构成,其数据量足以媲美其他工业的"大数据"。传统的图像物体分类与检测算法及策略难以满足图像视频大数据在处理效率、性能和智能化等方面所提出的要求 。深度学习通过模拟类似人脑的层次结构建立从低级信号到高层语义的映射,以实现数据的分级特征表达,具有强大的视觉信息处理能力,因而, 在机器视觉领域,深度学习的代表--卷积神经网络(Convolutional Neural Network, CNN)得以广泛应用。
20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络(CNN) 。现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。实质上,CNN就是通过模仿细胞视觉信息的处理过程而构建的多层Hubel-Wiesel结构 。
CNN和普通的神经网络具有许多相似之处,它们都是模仿人类神经的结构,由具有可学习的权重和偏置常数的神经元组成。每一个神经元可以接收输入信号,经过运算后输出每一个分类的分数。但是,CNN的输入一般是图像,卷积网络通过一系列方法,成功将数据量庞大的图像识别问题不断降维,最终使其能够被训练。CNN利用该特点,把神经元设计成具有三个维度:width, height, depth。

传统神经网络示意图
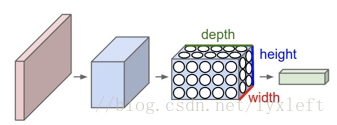
卷积神经网络示意图
那么,一个卷积神经网络由很多层组成,输入和输出均是三维的。有些层有参数,有些层则不需要参数。
卷积神经网络通常包括以下几种层:
☞卷积层(Convolutional layer),卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
☞线性整流层(Rectified Linear Units layer, ReLU layer),这一层神经的活性化函数(Activation function)使用线性整流(Rectified Linear Units, ReLU)f(x)=max(0,x)。
☞池化层(Pooling layer),通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
☞全连接层( Fully-Connected layer), 把所有局部特征结合变成全局特征,用来计算最后每一类的得分。
卷积层
卷积层的作用是通过对Hubel-Wiesel简单细胞的模拟检测其前驱层特征的局部连接。它是通过对输入图像进行多次卷积操作,提取出不同的特征图;然后把当前层的每个单元与前驱层的特征图局部块通过权值建立连接并进行局部加权和非线性变换。数学上,由特征映射实现的过滤操作被称为离散卷积,CNN也因此而得名。卷积层有以下几个关键点:
1.局部感知(Local Connectivity)
普通神经网络的输入层和隐含层为 "全连接(Full Connected)"的设计,这若沿用到卷积神经网络中,从计算的角度来讲,相对较小的图像从整幅图像中计算特征是可行的。但是,如果是更大存储量的图像,要通过这种全联通网络的这种方法来学习整幅图像上的特征,计算将变得非常耗时。举例来看,若设计104个输入单元,假设要学习的特征有100个,那么就有106个参数需要去学习。与28x28的小块图像相比较,96x96的图像使用前向输送或者后向传导的计算方式,计算过程也会慢102倍。
卷积层的本质便是解决此计算量爆炸的问题。它的方法是通过限制隐含单元和输入单元间的连接而实现:每个隐含单元仅仅只能连接输入单元的一部分,而非全部。每个隐含单元连接的输入区域大小称为该神经元的感受野(receptive field)。由于卷积层的神经元是三维结构,具有深度,卷积层的参数包含一系列的过滤器,每个过滤器训练一个深度。对于输出单元的不同深度处,与输入图像连接的区域是相同的,但是参数(过滤器)不同。
虽然每个输出单元只连接输入的一部分,但是值的计算方法是权重和输入的点积加上偏置,这与普通神经网络是一样的,如下图所示。

单个神经元运算图示
2. 空间排列
如前文所述,一个输出单元的大小可由三个量控制,即:深度(depth), 步幅(stride),和补零(zero-padding)。
深度(depth) : 又名:depth column。顾名思义,它控制输出单元的深度,也就是filter的个数,表示连接同一块区域的神经元个数。
步幅(stride):它控制在同一深度的相邻两个隐含单元,与他们相连接的输入区域的距离。若步幅很小(比如 stride = 1),相邻隐含单元的输入区域的重叠部分会很多; 步幅很大则重叠区域变少。
补零(zero-padding) : 通过在输入单元周围补零来改变输入单元整体大小,从而控制输出单元的空间大小。
可以用以下公式计算一个维度(宽或高)内一个输出单元里可以有几个隐藏单元:
(W-F+2P)/S+1(注释:W : 输入单元的大小(宽或高);F : 感受野(receptive field);S : 步幅(stride);P : 补零(zero-padding)的数量;K : 深度,输出单元的深度。如果计算结果不是一个整数,则说明现有参数不能正好适合输入,步幅(stride)设置的不合适,或者需要补零。)
3. 参数共享
应用参数共享,可以大量减少参数数量。
参数共享基于一个假设:如果图像中的一点(x1, y1)包含的特征很重要,那么它应该和图像中的另一点(x2, y2)一样重要。换种说法,我们把同一深度的平面叫做深度切片(depth slice),那么同一个切片应该共享同一组权重和偏置。我们仍然可以使用梯度下降的方法来学习这些权值,只需要对原始算法做一些小的改动。这里共享权值的梯度是所有共享参数的梯度的总和。
为什么要权重共享呢?一方面,重复单元能够对特征进行识别,而不考虑它在可视域中的位置。另一方面,权值共享使得我们能更有效的进行特征抽取,因为它极大的减少了需要学习的自由变量的个数。通过控制模型的规模,卷积网络对视觉问题可以具有很好的泛化能力。
池化层
池化即层下采样的过程,目的是为了减少特征图。
池化本身的具体操作是:首先,通过粗粒化各特征的位置,避免相对位置导致所形成主题的微小变化,以此实现主题的可靠检测。其次,每个典型的池化单元通常计算一个或几个特征图内局部块的最大值;而相邻单元则通过行或列平移形成的块来获取输入数据,从而降低特征表达维度,并对平移和扭曲等较小形变具有鲁棒性。
池化操作对每个深度切片独立,规模一般为 2*2,相对于卷积层进行卷积运算,池化层进行的运算一般有以下几种:
※最大池化(Max Pooling)。取4个点的最大值。这是最常用的池化方法。
※均值池化(Mean Pooling)。取4个点的均值。
※高斯池化。借鉴高斯模糊的方法。不常用。
※可训练池化。训练函数,接受4个点为输入,出入1个点。不常用。
下图为规模为2*2, 步幅为2,对输入的每个深度切片进行下采样的示意图。每个最大池化操作对四个数进行,如下图所示。
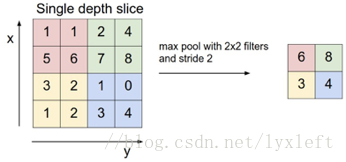
2*2规模池化示意图
池化操作将保存深度大小不变。如果池化层的输入单元大小不是2的整数倍,则一般采取边缘补零的方式补成2的倍数,然后再进行池化操作。
根据实际需要可以串联多个卷积、非线性变换和池化阶段,通常再叠加一个全连接层(即分类器) 来构建深度网络,然后通过BP算法等有监督地训练所有过滤器中的权值参数。
全连接层和卷积层可以互相转换:对于一个卷积层,只要把权重变成一个维度巨大的矩阵,其中大部分元为0,对应局部感知的区块有值,并且由权重共享,配置好一些元表示的权值,令之相同,即可转变成全连接层。而对于一个全连接层也可以操作变为卷积层。例如,一个K=4096 的全连接层,输入层大小为 7∗7∗512,它可以等效为一个 F=7, P=0, S=1, K=4096 的卷积层。
常见的CNN架构是:多个"卷积层+整流层"后面加一个池化层,重复这样的结构模式多次,达到满意的效果后,最后用全连接层控制输出。
目前,已有许多学者构建了一系列知名的卷积神经网络 :
LeNet. The first successful applications of Convolutional Networks were developed by Yann LeCun in 1990's. Of these, the best known is the LeNet architecture that was used to read zip codes, digits, etc.
ZF Net. The ILSVRC 2013 winner was a Convolutional Network from Matthew Zeiler and Rob Fergus. It became known as the ZFNet (short for Zeiler & Fergus Net). It was an improvement on AlexNet by tweaking the architecture hyperparameters, in particular by expanding the size of the middle convolutional layers.
GoogLeNet. The ILSVRC 2014 winner was a Convolutional Network from Szegedy et al. from Google. Its main contribution was the development of an Inception Module that dramatically reduced the number of parameters in the network (4M, compared to AlexNet with 60M). Additionally, this paper uses Average Pooling instead of Fully Connected layers at the top of the ConvNet, eliminating a large amount of parameters that do not seem to matter much.
VGGNet. The runner-up in ILSVRC 2014 was the network from Karen Simonyan and Andrew Zisserman that became known as the VGGNet. Its main contribution was in showing that the depth of the network is a critical component for good performance. Their final best network contains 16 CONV/FC layers and, appealingly, features an extremely homogeneous architecture that only performs 3x3 convolutions and 2x2 pooling from the beginning to the end. It was later found that despite its slightly weaker classification performance, the VGG ConvNet features outperform those of GoogLeNet in multiple transfer learning tasks. Hence, the VGG network is currently the most preferred choice in the community when extracting CNN features from images. In particular, their pretrained model is available for plug and play use in Caffe. A downside of the VGGNet is that it is more expensive to evaluate and uses a lot more memory and parameters (140M).
ResNet. Residual Network developed by Kaiming He et al. was the winner of ILSVRC 2015. It features an interesting architecture with special skip connections and features heavy use of batch normalization. The architecture is also missing fully connected layers at the end of the network. The reader is also referred to Kaiming's presentation (video, slides), and some recent experiments that reproduce these networks in Torch.
应用案例
本部分介绍深度学习在图像处理与机器视觉领域的研究和应用实例。
1.图像物体分类
物体分类是机器视觉领域的基本问题,是更高级、更复杂的视觉问题的基础。物体的分类一般是通过一些特征对图像进行全局描述,利用分类器操作来判定图像中是否存在某类物体。对于图像数据,深度学习具有优秀的建模和特征提取能力,已经在物体分类的理论分析和实际应用中广泛应用。
例如,Karpathy 等基于100万部含有487个类别的YouTube视频进行大规模的视频分类研究,通过多分辨率的小凹结构来加速CNN训练,使所提出的基于时空网络的模型相比传统上基于特征的模型在分类精度上具有明显提升。
Sanchez-Riera 等基 于 CNN 模 型 训 练 出 一 系 列 手 势 作 为样本来粗略预测手势的姿势和方向,并把此方法定义为一 个非严格模型算法;因为,即使其违反了手势平滑动作的时间 假设,此方法仍然可以获得手势的各项参数。
2.图像物体检测
物体的检测更注重局部特征,它有别于分类问题,是回答一张图像中在什么位置存在一个什么物体,所以除特征表达外,物体结构是物体检测区别于物体分类的最明显特点 。
Yi Sun等基于CNN设计出一个DeepID人脸识别系统,并通过增加验证和识别信号在人脸识别挑战LFW (Labeled Faces in the Wild) 数据库上取得了99.15%的识别率,首次超越同样数据集上人97.52%的识别率,最终通过模型的进一步完善,使DeepID系统拥有非常好的遮挡鲁棒性,这一成果也展示了深度卷积神经网络在机器视觉领域的强大应用潜力。


